
Un beau jour de mars 2021…
La catastrophe arriva.
Les serveurs OVH ont pris feu.
Et nos données… Avec.
Au-delà du bref rappel que tout ce qui est digital est finalement très physique, nous avons également pu voir l’impact énorme sur notre application de géodata, Smappen.
Où la donnée est centrale. C’est notre cœur de métier.
Notre ADN et challenge de tous les jours : une application à jour, fiable, rapide, performante, complète.
Aujourd’hui nous proposons des données des bases INSEE, SIRENE, recensements US, Belgique…
Et nous continuons d’implémenter toujours plus de données pour répondre aux besoins de nos clients.
Alors… Les questions sont les suivantes :
- Comment être plus réactif en cas de catastrophe ?
- Comment éviter l’indigestion en implémentant un max de données ?
Comment tout a commencé
Pour commencer, l’équipe était réduite : 1 développeur.
Pour arriver à des premiers résultats efficacement, il a donc été au plus simple :
L’opération d’acquisition et de stockage de ces données était manuelle.
Ca ne pose pas de problème tant que la quantité de données et le nombre de développeur n’augmente pas.
Prévenir les soucis
Quand les soucis commencent à arriver…
Quand le datacenter hébergeant nos bases de données prend feu…🔥
C’est le branle-bas de combat !
Il faut reconstruire toute ces bases de données et la documentation est incomplète.
En plus, certaines données externes étaient également hébergées dans ce datacenter.
Nous n’y avions donc plus accès. Il faut donc aller retrouver les données directement à la source (recensement des différents pays que les serveurs officiels de chacun)
Grandir de manière cohérente
Avec une quantité de données grandissante, et le besoin de reconstruire nos données en cas de catastrophe, il faut être capable de les maintenir à jour.
Pour améliorer notre réactivité en cas de catastrophe mais aussi pour faire face à une quantité de données grandissante : nous devions mettre à jour nos données plus régulièrement.
En plus, notre CEO demande qu’on soit capable de mettre à jours ces données en moins de 15 jours ! Il pense que nous avons mieux à faire.
Allez, au boulot…
Premier réflexe : documenter
Commençons par les bases.
Notre première approche : documenter pas à pas le chemin pour reconstruire ces données.
Merci à Notion qui nous garde toutes ces informations au chaud.
Les procédures sont un peu complexes mais elles doivent nous permettre de rétablir notre service en toutes circonstances.
Les limitations
Malgré une documentation correcte, plusieurs problèmes persistent :
- En cas de problème, la reconstruction de la base de données prend plusieurs jours
- Avec le nombre croissant de données la documentation se complexifie
- Certaines données dépendent de données précédemment importées
- Dans le cas où certaines données ne sont plus disponibles, il n’est plus possible de les retrouver
- La mise à jour de ces données devient compliquée. Certaines de nos sources de données sont mises à jour mensuellement. Il n’est pas possible de faire des opérations manuelles si souvent.
Ensuite : on automatise
Problématique
Les données présentées à nos utilisateurs sont variées :
- Données ponctuelles (liste d’entreprises)
- Données de surface (contours des IRIS, codes postaux ou communes)
- Données numériques (recensements rattachés à des données de surface)
Les objectifs d’automatisation que nous nous souhaitons atteindre sont :
- Pouvoir planifier périodiquement les tâches d’ingestion des données,
- Enchaîner plusieurs traitements
- Agréger des données issues de plusieurs sources (données surfaciques + données numériques en particulier),
- La description des tâches doit être suffisamment simple pour tenir lieu de documentation.
Nos données doivent être disponibles dans une base de données PostgreSQL (avec l’extension postGIS pour la gestion des données géographiques).
Un chef d’orchestre
Pour remplacer nos petites mains lors de l’exécution des procédures, nous avons décidé d’utiliser un orchestrateur.
Un orchestrateur permet d’enchaîner des traitements et de gérer les dépendances entre ces différents traitements.
Il présente en général aussi une synthèse claire des opérations effectuées avec leur statut.
Il nous faut ensuite créer une série de traitements unitaires qui pourront être enchaînés par notre orchestrateur.
Nous avons identifiés les traitements suivants:
- Télécharger un fichier
- Décompresser un fichier (zip, tar.gz, …)
- Lire les données d’un fichier de données CSV/XLS et écriture en base de données
- Lire un fichier de données géographiques (GeoJSON, Shapefile) et écriture en base de données
- Exécuter des opérations sur la base de données afin d’agréger les données issues de plusieurs sources.
À partir de ces traitements, nous espérons pouvoir réaliser toutes nos chaînes de traitement. 🤞
Le choix de la solution technique
Bon on va rentrer dans le coeur du réacteur, ça va devenir un peu plus technique 🔧.
Il existe de nombreux outils d’orchestration.
Pour notre benchmark nous en avons retenus 3 :
Google Cloud Workflow
➕ Saas, aucune administration
➕ Simple
➕ peu cher. Paiement à l’exécution
➖ Ne s’occupe que de l’orchestration. Nécessite une autre solution pour l’exécution a proprement parlé
➖ Ne propose pas non plus d’exécution périodique
Apache Airflow
➕ La référence
➕ Opensource
➖ Complexe à utiliser
Argo Workflow
➕ Opensource
➕ Simple
➕ Basé sur kubernetes que nous utilisons déjà
➖ Moins réputé
A l’issu de notre benchmark, Argo Workflow a gagné nos cœurs. 🎉
Argo Workflow

Argo Workflow nous permet de construire des tâches de traitement, de les enchaîner et de nous présenter le résultat sous une forme graphique.
Chaque traitement doit être défini sous la forme d’un container Docker.
Ce container pourra prendre en entrée un fichier de données, ou simplement des paramètres de configuration.
Il sera exécuté, puis le résultat de son exécution pourra être transmis au container suivant.
Par exemple, le traitement effectué pour les données de recensement Autrichien est représenté de la manière suivante :
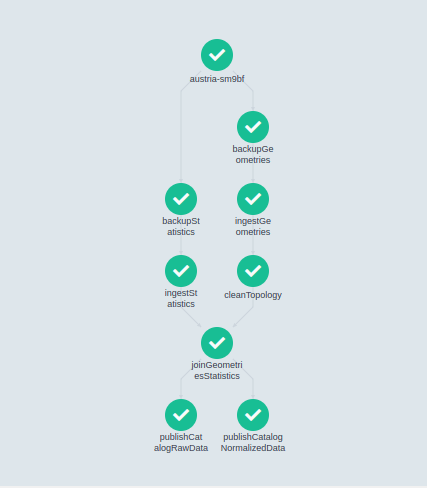
backupGeometriesetbackupStatisticspermettent d’effectuer un backup des données issues de l’organisme de sondage autrichien.ingestStatisticsetIngestGeometriesenregistrent en base de données respectivement les données statistiques (numériques) et les données géographiques (contours de chaque zone de recensement).joinGeometriesStatisticspermet de faire la liaison entre les données géographiques et les données statistiques. À partir de cette étape, nous avons à notre disposition des données sur lesquelles notre application peut faire des recherches.cleanTopologypermet de nettoyer nos géométries et de s’assurer que nous avons une base saine pour la suite de nos traitements géographiques.- les 2 tâches finales
publishCatalog...inscrivent dans la base de données le compte rendu de l’acquisition. Nous avons ainsi un catalogue de données permettant de connaître les sources et les traitements sur chacune de nos données disponibles.
Nous avons maintenant un chef pleinement rassuré et nous pouvons manipuler confortablement un plus grand volume de données.
Ce qui va nous aider grandement pour ce que nous avons prévu à l’avenir !
Stay tuned 😉

Benoît Goudy
Architecte logiciels
Notre homme à tout faire… Quand il s’agit de code et de trucs bizarres 😉
Cet article fait partie d’une série d’articles pour fêter le million d’euros de chiffre d’affaires annuel. Découvrez les autres récits !

Dan Faudemer
CEO & Fondateur
Les débuts : "traverser le fossé", récit d'une aventure SaaS
De la simple application de calcul d’isochrone à une plateforme de géomarketing : comment et pourquoi Dan a créé Smappen ?
Retour sur une aventure entrepreneuriale plutôt originale !

Laurent Leclerc
Co-fondateur & Business Developer
Pourquoi nous n'avons pas levé de fonds en tant que start-up
La question qui revient le plus souvent de la part de nos clients et utilisateurs : « avez-vous levé des fonds ? » ou « qui sont vos investisseurs ? ».
Car qui dit start-up… Dit souvent levée de fonds.
Mais Dan et Laurent, co-fondateurs de Smappen, ont fait le choix d’une croissance organique, dénuée de levée.

Laura Birot
Marketing Manager
Changer le nom de notre start-up en 3 mois
Vous vous souvenez d’OALLEY ?
Nous, oui !
En mars 2022, OALLEY est devenu Smappen.
Pourquoi ce changement de nom ?
Et comment nous avons pu réaliser ce changement en trois mois ?
Retour sur l’aventure avec Laura, Marketing Manager.

